Guest post: Nathan Aw, Blockchain Engineer

Hyperledger Fabric v1.2 (HLF v1.2) is truly, truly an exciting release. I have been long awaiting this release, as it addresses some of the challenges I personally encountered when using Hyperledger Fabric.
Before I share the full list of exciting new features in HLF v1.2, some context is first needed.
Context
Privacy and scalability are the foremost reasons why organisations choose permissioned/consortium blockchains/DLTs over the public ones.
With Hyperledger Fabric, privacy is enabled through the use of channels. The channel design is elegant, providing a number of sub-networks across a larger Hyperledger Fabric network.
However, there some downsides introduced with the initial channel design. After much industry experimentation with Hyperledger Fabric, the v1.0 channels design was a common frustration. To take one example, SWIFT completed a POC and one of the observation/findings was “…to productise the solution, more than 100,000 channels would need to be established and maintained, covering all existing Nostro relationships, presenting significant operational challenges.”
Instead of setting up many multiple channels, private data collections are introduced. This feature is the most important update in the 1.2 release. One of the features of Fabric is the concept of channels, but the overall service sees everything within the channel, so it has access to the payload of a transaction even though it might not be required to do so. From a privacy perspective, there’s still access to it and so private data collections actually give you more control in allowing transactions to be made private.
High-Level Features in HLF v1.2
From the What’s New in v1.2, some of the major highlights rolled out in HLF v1.2 are:
- Private Data Collections: A way to keep certain data/transactions confidential among a subset of channel members.
- Service Discovery: Discover network services dynamically, including orderers, peers, chaincode, and endorsement policies, to simplify client applications.
- Access control: How to configure which client identities can interact with peer functions on a per channel basis.
- Pluggable endorsement and validation: Utilize pluggable endorsement and validation logic per chaincode.
Improvements to privacy design and setup simplification (service discovery) is a key focus in this release. Not to worry if some of these terms above are new to you as a primer is provided below.
Fundamentals First – Definitions (see the Hyperledger Fabric Glossary for more details)
Channel:
A channel is a private blockchain overlay which allows for data isolation and confidentiality. Channels are defined by a Configuration-Block, which contains configuration data that specifies members and policies.
Channel-specific Ledger:
A channel-specific ledger is shared across the peers in the channel, and transacting parties must be properly authenticated to a channel in order to interact with it
Private Data Collections:
Used to manage confidential data that two or more organizations on a single channel want to keep private from other organizations on that channel. The collection definition describes a subset of organizations on a channel entitled to store a set of private data, which by extension implies that only these organizations can transact with the private data.
Private Data:
Confidential data that is stored in a private database on each authorized peer, logically separate from the channel ledger data. Access to this data is restricted to one or more organizations on a channel via a private data collection definition. Unauthorized organizations will have a hash of the private data on the channel ledger as evidence of the transaction data. Also, for further privacy, hashes of the private data go through the Ordering-Service, not the private data itself, so this keeps private data confidential from the Orderer.
Now that we have some of the background, context and terminology covered, let’s get into the nitty gritty of private data, which is the key feature in the HLF v1.2 release.
Private Data – Background, Context and Problem Statement for Private Data Collections
Before HLF v1.2, when a group of organizations on a channel needed to keep data private from other organizations on that channel, they had the option to create a new channel comprising just the organizations who needed access to the data.
However, creating separate channels in each of these cases creates additional administrative overhead (maintaining chaincode versions, policies, MSPs, etc), and doesn’t allow for use cases in which you want all channel participants to see a transaction while keeping a portion of the data private.
Therefore, we need private data within a channel solution – a private data collection. Some use cases of private data collection could be building a GDPR compliant blockchain and/or privacy-focused use cases such as selectively sharing of health care to the only certain partners.
A high-level diagram is shown below:
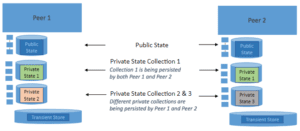
Let’s take a look at a sample policy json configuration file – the json configuration file.
Collection Definition JSON
[
{
“name”: “collectionMarbles”,
“policy”: “OR(‘Org1MSP.member’, ‘Org2MSP.member’)”,
“requiredPeerCount”: 0,
“maxPeerCount”: 3,
“blockToLive”:1000000
},
{
“name”: “collectionMarblePrivateDetails”,
“policy”: “OR(‘Org1MSP.member’)”,
“requiredPeerCount”: 0,
“maxPeerCount”: 3,
“blockToLive”:3
}
]
Pay careful attention to the key “policy” here. There are two collections, collectionMarbles and collectionMarblePrivateDetails, for which different policy is enforced.
The collectionMarblesPrivateDetails collection allows only members of Org1 to have the private data in their private database.
The full tutorial to private data collection, which I have already gone through, was really instructive. You could run through the tutorial at https://hyperledger-fabric.readthedocs.io/en/release-1.2/private_data_tutorial.html
As always, feel free to reach out to me at nathan.mk.aw@gmail.com if you have challenges with the setup.
Conclusion
Being both a Hyperledger and Enterprise Ethereum DLT practitioner in the finance industry within the capital markets, the introduction of private data collection in the Hyperledger Fabric v1.2 release is a real game changer. Instead of creating multiple separate channels among participants to achieve privacy needs, you need only to create one channel to keep chaincode data confidential among a subset of channel members.
Speaking from personal experience, having to evaluate, build and operate DLT solutions in a production environment/setting that can scale, private data collection in v1.2 release really makes scaling up and operating a lot easier.
Enjoy building your distributed application on top of Hyperledger Fabric v1.2 and as always, feel free to ask me any questions relating to Hyperledger at nathan.mk.aw@gmail.com and/or connect with me on linkedin – https://www.linkedin.com/in/awnathan/
SOURCE:
https://hyperledger-fabric.readthedocs.io/en/release-1.2/private-data/private-data.html
https://hyperledger-fabric.readthedocs.io/en/release-1.2/private_data_tutorial.html
https://wiki.hyperledger.org/projects/fabric/roadmap
https://github.com/hyperledger/fabric-samples/tree/master/chaincode/marbles02_private
https://hyperledger-fabric.readthedocs.io/en/release-1.2/private_data_tutorial.html
https://www.swift.com/news-events/news/swift-completes-landmark-dlt-proof-of-concept
https://hyperledger-fabric.readthedocs.io/en/release-1.2/glossary.html
https://www.hyperledger.org/blog/2018/07/24/hyperledger-sawtooth-seth-and-truffle-101