1. Performance Evaluation Terms
Figure 1 shows a typical configuration for a blockchain performance evaluation. The Test Harness on the left shows the program and system(s) used to generate load against the System Under Test (SUT) on the right. Each of the terms in Figure 1 is defined in this section.
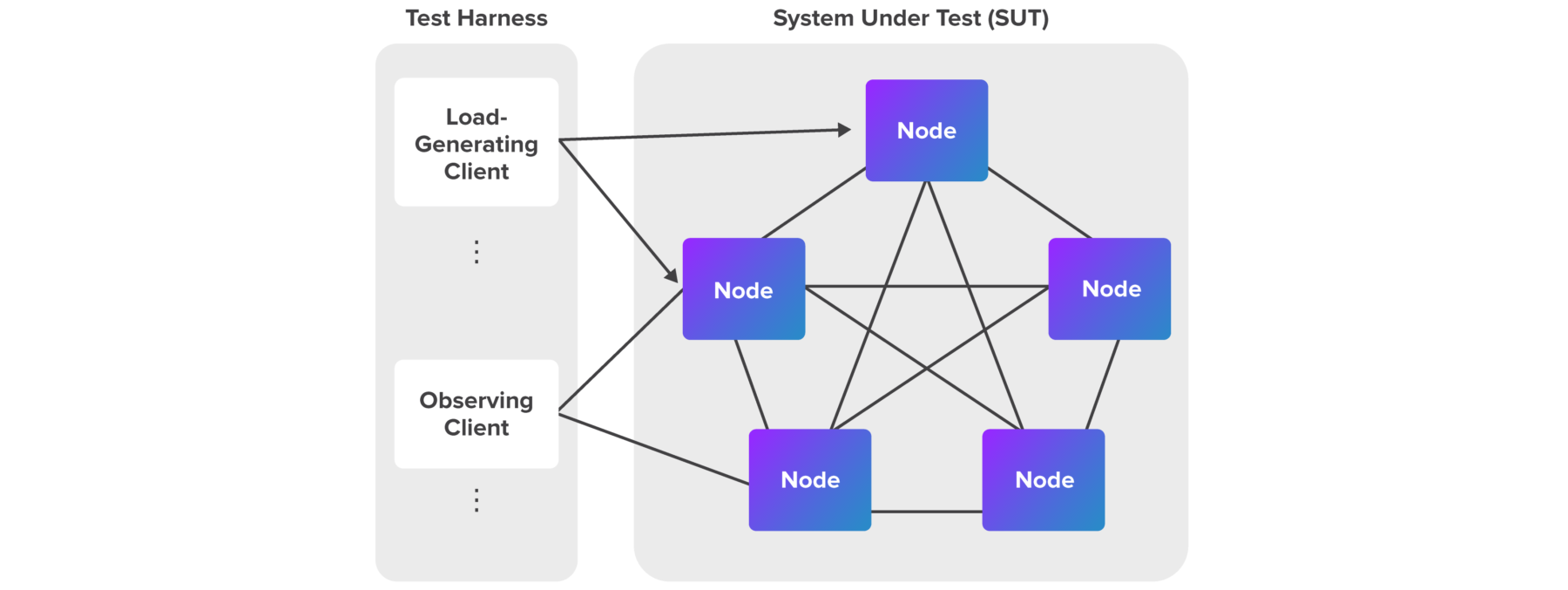
Figure 1: Typical Configuration for a Blockchain Performance Evaluation
Test Harness
The test harnessis the hardware and software used to run the performance evaluation. This test harness will typically represent many clients that can inject workloads and make observations at any number of nodes.
Client
A client is an entity that can introduce work into a system or invoke system behaviors. In a blockchain system, there are often multiple types of clients at multiple levels.
For example, in a supply chain application using smart contracts deployed to a blockchain, the supply chain application is a client of the blockchain platform. However, further clients of the supply chain application will often interact with the application via a browser. Another client might be the user of an auditing component of the supply chain application who is notified of policy violations via an email or SMS message.
For the purposes of this paper, we will focus on the entities that directly interact with the blockchain platform, not on any applications built on top of those platforms.
A load-generating client is a node that submits transactions on behalf of the user to the blockchain network (SUT), most often following an automated test script. The interface between the client and the SUT can range from a simple Representational State Transfer (REST) interface to a comprehensive Software Development Kit (SDK). Depending on the interface, a client can be either stateless or stateful.
An observing client is a node that receive notifications from the SUT or can query the SUT regarding the status of the submitted transactions, most often following an automated test script. There can be more than one observing client. The observing client cannot submit any new transactions.
System Under Test (SUT)
Defining the System Under Test (SUT) is a complex issue. For the purposes of this document, the SUT is defined as the hardware, software, networks, and specific configurations of each required to run and maintain the blockchain.
The SUT does not include the client APIs, any associated libraries, or any external caches or databases being used to accelerate read times.
Node
In the context of a blockchain network, a node is an independent computing entity that communicates with other nodes in a network to work together collectively to complete transactions.
A node is a virtual entity, in the sense that it could be running on physical hardware, or as a VM or containerized environment. In the latter case, a node could share physical hardware with other nodes in the same network.
A set of nodes may be managed by the same organization. For example, think of a mining pool operated by one company where a group of machines run as individual nodes doing proof of work (PoW) on a network.
In most blockchain networks (Bitcoin, Ethereum, Hyperledger Burrow, Hyperledger Indy, Hyperledger Iroha, Hyperledger Sawtooth) each node plays a uniform class of roles in the network, such as generating blocks, propagating blocks, and so on. In these networks, nodes are usually referred to as peers. Such networks might require one or more nodes to take on a temporary role as a leader. This leadership role may be passed to other nodes in certain well-determined conditions.
However, in some blockchain networks (such as Hyperledger Fabric), nodes are assigned one or more possible roles, such as endorsing peers, ordering services, or validating peers.
Appendix A: Latency Calculation Examples
This appendix describes three different cases that create different issues for measuring latency in blockchains. One case has immediate finality, and two have probabilistic finality with known and unknown topologies. Numbers are used for illustration purposes only and do not reflect the performance of any particular platform.
Case 1: SUT with Immediate Finality
Systems employing voting-based consensus have immediate finality. Once a transaction is committed, the state is guaranteed to be irrevocable. As with the remaining cases, the test process should measure commitment at each node to ensure full commitment across the distributed system.
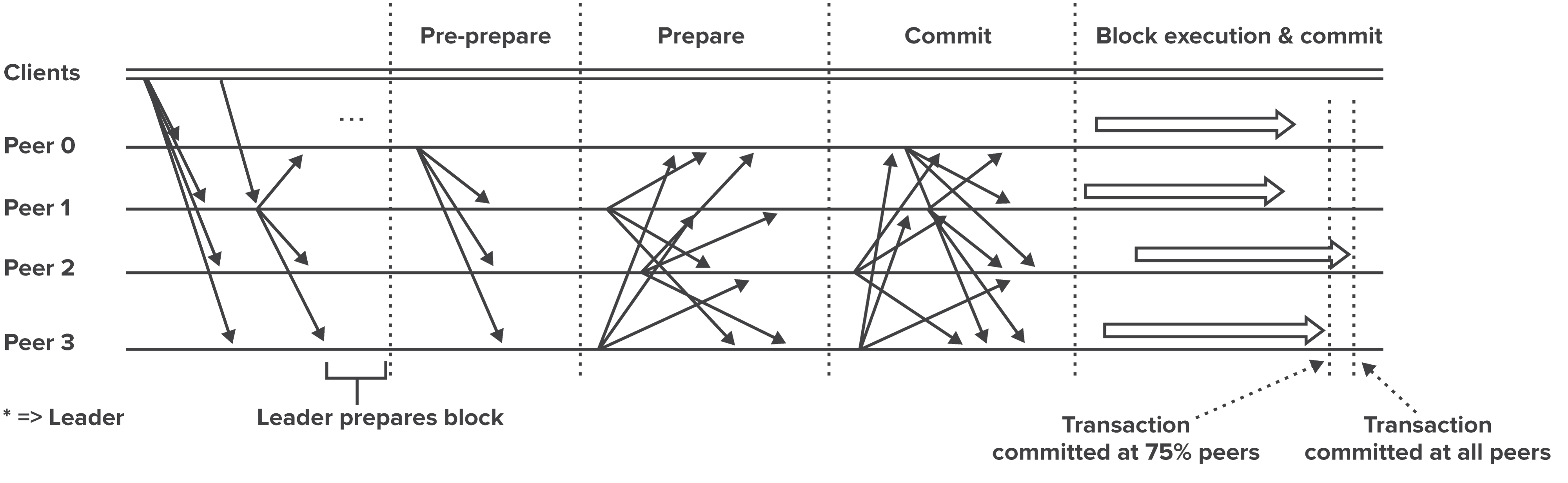
Figure 2: Transaction Flow for Blockchain Platforms using PBFT Consensus. Source.
Example: In a 10-node network running Min-BFT, 9 nodes commit a transaction after 11 seconds. The tenth node has a higher latency connection to the leader and takes an additional second. This transaction has an 12-second delay at 100% of the nodes.
Case 2: SUT with Probabilistic Finality and Known Topology
Systems using lottery-based consensus have probabilistic finality. In controlled performance testing, the topology will be known. This will likely be the case in most permissioned deployments. In this case, a transaction is confirmed only when multiple nodes reach the same state.
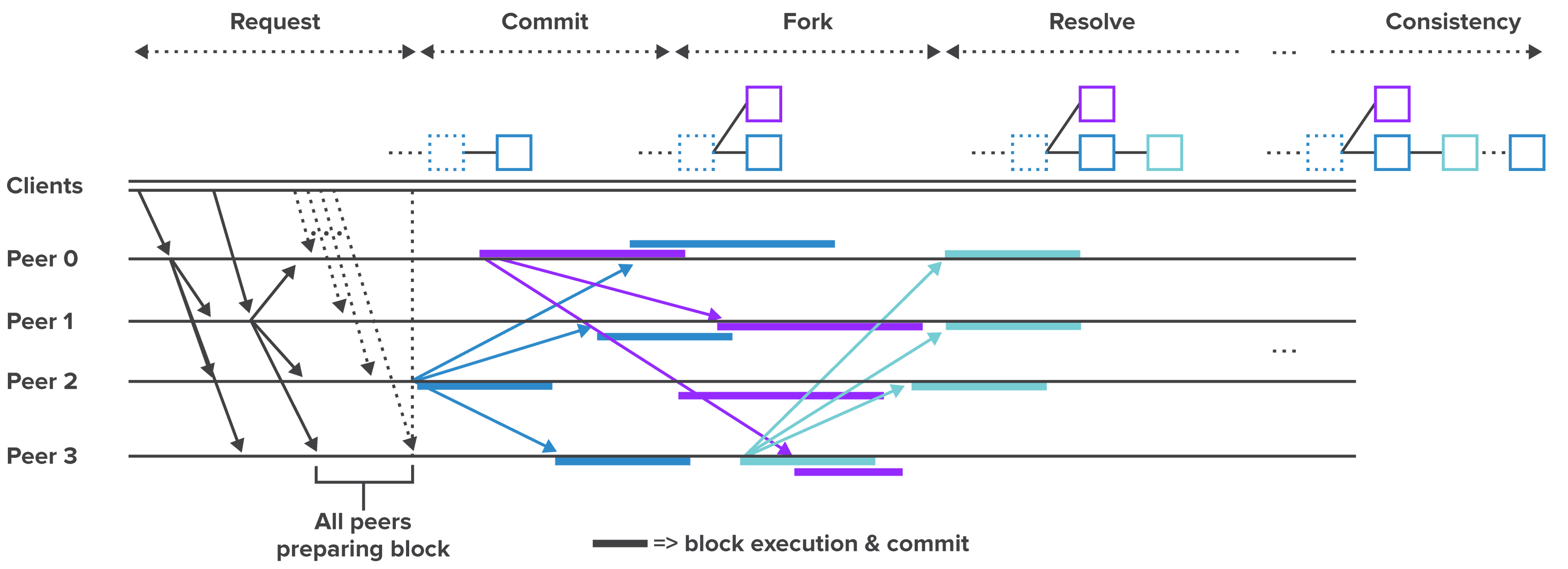
Figure 3: Transaction Flow for Blockchain Platforms using Random Leader Election Consensus. Source.
Figure 3 depicts transaction flow for platforms using random leader election consensus like PoW or proof of elapsed time (PoET). This form of consensus does not have discrete rounds like PBFT. However, the phases depicted in the diagram represent conceptual operations:
- Request—A client submits a transaction to the network.
- Commit—One validator publishes the transaction in a block to the network.
- Fork—Zero or more validators inadvertently publish competing blocks.
- Resolve—Upon receipt of the winning block, other validators resolve the fork.
- Consistency—Subsequent reads to any validator produce consistent results.
Since the eventual consistency of the network is probabilistic, this gives rise to using a percentage of the network as a threshold for measuring latency.
Example: In a 20-node network, running PoET, 19 nodes commit a transaction within 25 seconds after the client submitted it. The final node publishes a competing block which it rolls back during fork resolution, causing an additional 10-second delay. Table 1 lists the commit times at all 20 nodes.
As shown in Table 2, this transaction has a 25-second delay at a 95% threshold of nodes and a 35-second delay at a 100% of the nodes.
A company may require a 100% threshold, in which case the latency should be reported as 35 seconds at 100% of nodes.
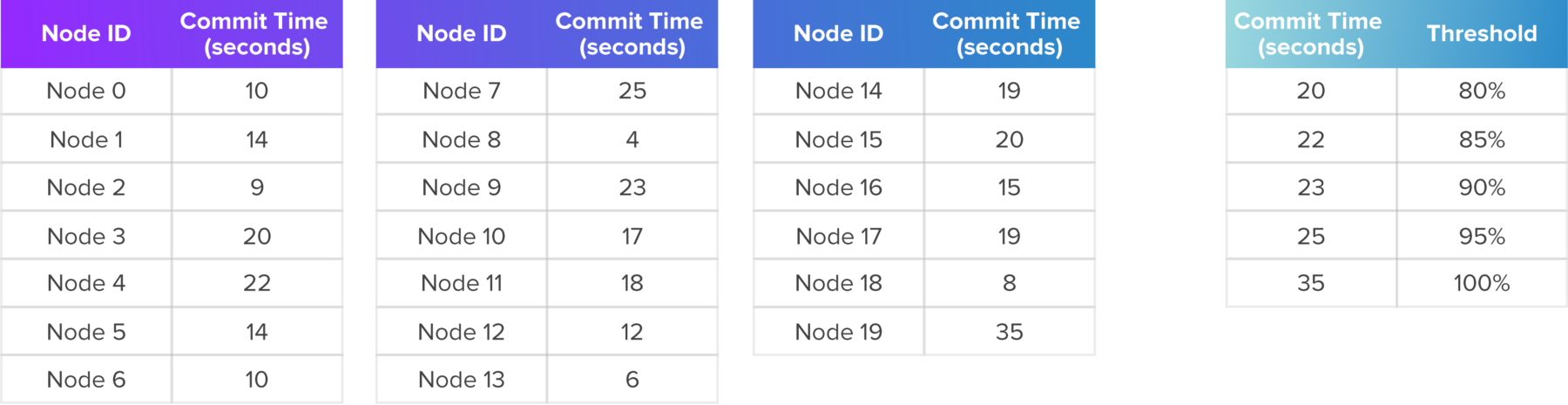
Table 1: Example Transaction Latency Data at 20 Nodes
Table 2: Example Transaction Latencies
at Various Network Thresholds
Case 3: SUT with Probabilistic Finality and Unknown Topology
Such a system is usually designed to run in an untrusted environment with anonymous “miners.” Only limited access points are revealed to the client. In this case, the confirmation should be delayed until enough blocks are chained behind the block/transaction.
For example, in Bitcoin, a delay of six blocks is usually considered sufficient to confirm the transaction. A performance test tool can estimate this by recording the block in which each transaction shows up. This data can be used to do a percentile analysis, so we can estimate the percentile of transactions committed up to a certain block, as shown in Figure 4 below. An organization can use this metric for risk assessment of their transactions.
Example: A transaction submitted when block x is the highest can be found in block (x + 2) with 50th percentile chance, in block (x+5) with 90th percentile chance, in block (x+7) with 99th percentile chance. Thus the transaction latency is 2 blocks at 50th percentile, 5 blocks at 90th percentile, and 7 blocks at 99th percentile respectively. In case blocks are generated with variable frequency, this can also be visualized by time.
Note that this measurement would vary with the average block size (in kB or average number of transactions per block), block frequency, and network size.
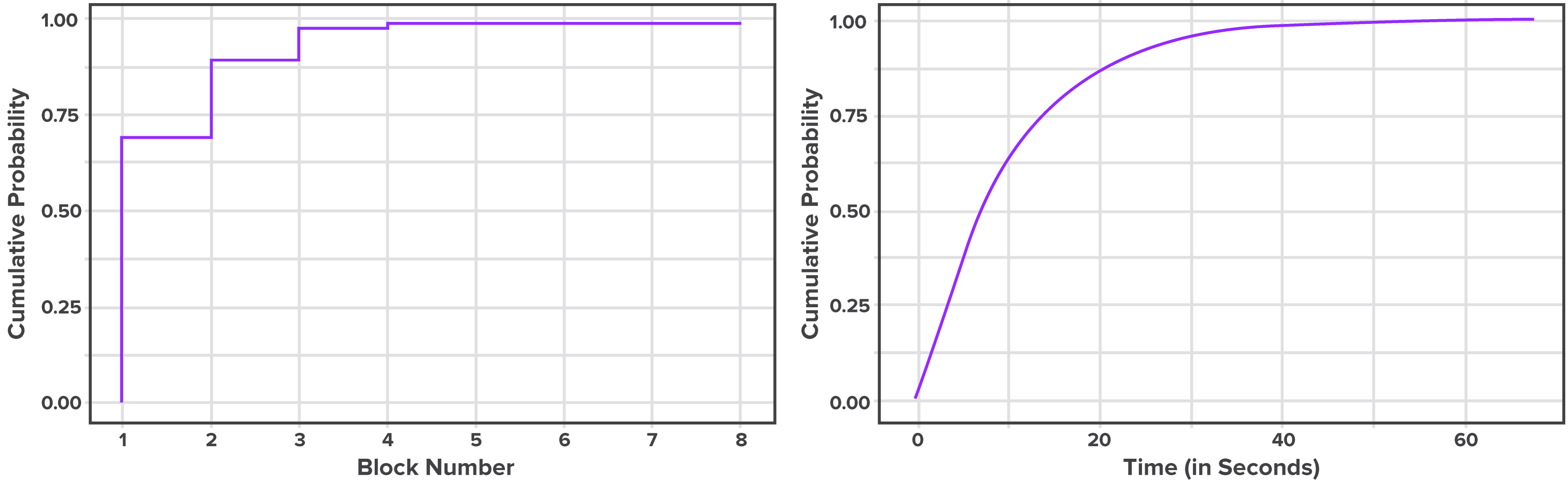
Figure 4: Transaction Confirmation Probability. Source.